XML 구조의 기본 요소는 요소(Element)와 내용(Content)이다. 즉 아래와 같이 각 요소에 따른 내용인 값을 입력하면, 컴퓨터가 인식이 가능하다록 한다는 점.

아래와 같은 각각의 계층값이 다르다 하더라도, Dart Taxonomy 로 통일되어 했을 경우엔 동일한 개념을 통해 인식이 가능하다.

이를 재무제표를 더 깊숙하게 봐보면 알 수가 있다. 아래와 같이 각각의 내용을 메타 데이터 형식으로, 개념, 값,상황 정보 등으로 구분이 가능할 것이다. 여기에선 주로 Concept, Fact 등으로 구분하는 것같다. 사실상은 이러한 정보값을 각 사실(Fact) 별로 구조화 하는 것.

여기에선 또 텍사노미 문서라고, 이러한 개념을 정의하고 구조화하는데에 한국에선 Dart Taxonomy를 이용한다. 이는 IFRS Element - 5242개, DART Element - 1769개 (비금융업 주석, 금융업 본문, gcd 포함) 를 가진다고 한다. 각 요소의 속성은 아래와 같다.

택사노미부터 보자.
기본적으로 택사노미 문서는 Schema 와 Linkbase 로 구성돼 있는데, 보통 아래와 같다고 한다. 5개 파일을 생성하는데, schema, label, definition, presentation, calculation 인 듯 하다.
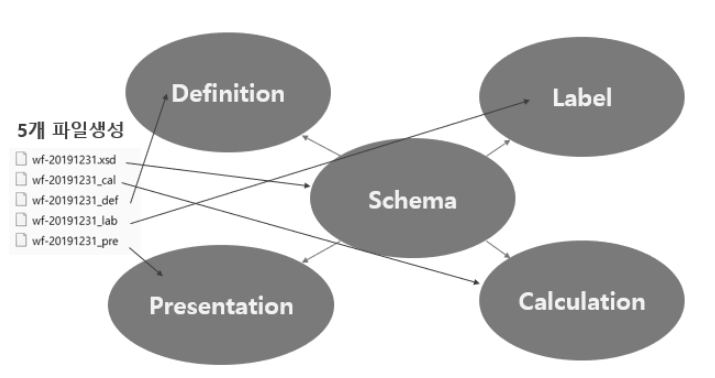
각각의 항목을 주로 살펴본다면, 먼저 Schema 는 XBRL보고서를 구성하기 위한 기본정보를 정의 하고, 네임스페이스(Namespace), 링크(linkbaseRef), 임포트(import) 영역, 롤 타입(Role type), 보고서 요소(element)에 대한 정의를 한다고 한다. 파일명은 xsd 로 쓰인다.
표시 링크(Presentation Link): 보고서의 체계(Hierarchy)를 정의하는데, 적어도 계정 과목 등을 체계적으로 이어주는 역할을 하는듯 하다. 파일명은 pre 로 쓰인다.

정의 링크(Definition Link) 는 각 보고서 요소(Element)간의 관계가 유효한 것임을 정의하는데, 이는 선택 사항이지만 보고된 사실이 일관되고 의미가 있는지 확인하기 위해 차원(Dimension)을 구성할 때는 반드시 정의한다고 한다. 파일명은 def 로 나온다.
이름 링크(label link) 는 아래와 같다. 개념의 여러 가지 이름들을 정의하는 듯 하다. 파일명은 lab 로 쓰인다.

마지막으로 계산검증 링크(Calculation Link)인데, 이는 계산검증을 통해 보고서의 정확성을 검사한다. 파일명은 cal 로 쓰임.

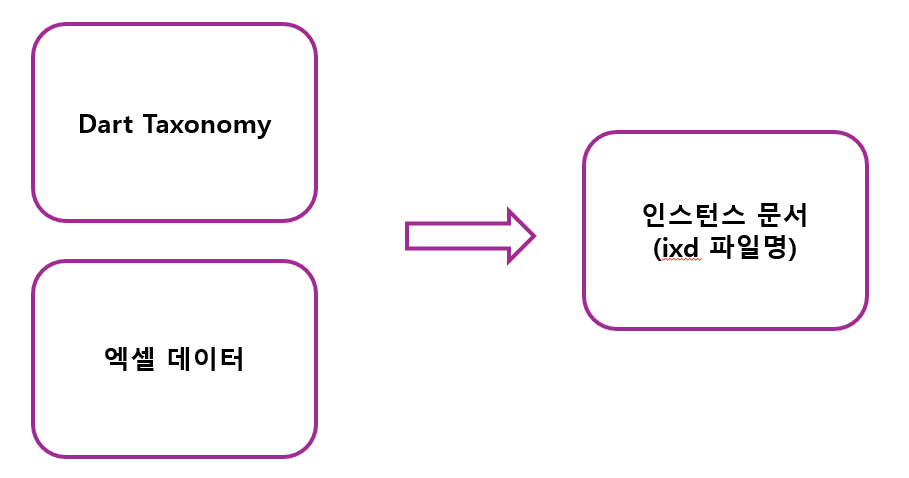
이제 Taxonomy 의 와꾸를 바탕으로 Instance를 생성하여 문서를 넣는다. 말 그대로, Dart 의 Taxonomy 를 바탕으로 표준화된 계정 과목 등으로 Instance 문서를 생성하여 안에 데이터 값을 넣어 DB화 한다는 의미.
마지막으로 Dimension 이라는 부분이 있다. 이는 주석에 나오는 테이블을 작성하는데 나오는 개념 값다. 축(Axis)으로 항목(Line Item)과 구성요소(Member)별로 값을 입력하는 경우 Dimension으로 구성된다고 하는데, 이를 쉽게 풀이하자면, member 는 컬럼 쪽이고, Line Item 은 행, 그리고 전체 테이블 자체를 Dimension 이라고 표현하는 듯 하다. 이는 피벗테이블만 비슷한 개념.

여기까지 고려한다면, 한마디로 다음과 같은 형식으로 정리된다. 즉, 회사가 쓰는 Taxonomy 가 있을 경우 이를 공용으로 만들어서 세팅, 이후 엑셀 데이터를 넣어 최종 인스턴스 문서를 만든다. 만일 최초 Taxonomy 를 세팅한다면 이를 위한 설계 작업이 별도로 필요하다. 그리고 Dart Taxonomy 가 별도로 업데이트 될 때마다 계속 수정하고 관리해줘야된다. 이에 아마 최초 XBRL 세팅시엔 이러한 설계 작업이 먼저 들어갈 것이고, 그 다음부턴 별도의 과정이 많이 생략되어 자동화로 진행될 거라 짐작됨.
댓글