오늘은 저만 그걸 사용했었는지도 모르겠어요. 오늘은 네이버 데이터 랩이라고 있습니다. 네이버 데이터 랩이라는 거를 여러 스마트 스토어 하시는 분들과 다른 분들이 많이 사용하시는 그런 것 중에 하나예요. 근데 이런 인기 트렌드 같은 것들을 보는 것도 좋죠.
근데 시간이 너무 오래 걸려요. 우리가 봐야 될 키워드만 하더라도 한 수백 가지가 되죠. 이러한 수백 가지를 빠르게 뭔가 볼 수 있는 이런 것을 저장도 하면 편하지 않습니까 그래서 이런 걸 저장도 해서 보면 어떨까 싶어서 오늘은 이러한 정보 크롤링 해놔서 검색량을 보고 그거에다 해서 데이터베이스에 집어넣어서 그거를 일간별로 자동으로 실행을 하게끔 하는 그런 작업을 만들어봤어요. 해서 목차는 다음과 같습니다.
목차
1. 파이썬 네이버 상품 인기 키워드 Top 500 크롤링하기
2. 파이썬 네이버 데이터랩 Top 500 키워드 검색량 뽑기
3. 파이썬 네이버 데이터랩 Top 500 키워드 MS SQL에 집어넣기
4. 파이썬 윈도우 작업 스케쥴러 자동화 작업
파이썬 네이버 상품 인기 키워드 Top 500 크롤링하기
크롤링을 하고요 그다음에 검색량을 뽑고 db에 집어넣고 그거를 컴퓨터가 알아서 일정 시간에 자동으로 크롤링 할 수 있도록 이 뽑는 겁니다. 첫 번째 같은 경우에는 이거는 길기는 해요. 난이도가 있기는 합니다. 처음으로 파이썬 네이버 상품 인기 키워드 top 500 크롤링하기인데요, 여기 안에서 보시면 난이도가 있기는 합니다. 근데 그렇게 큰 난이도가 있다거나 그렇게 생각하지는 않아요. 그 정도로 이렇게 큰 난이도다라는 그것까지는 아닌데 그래도 처음 하시는 분들이라면 조금 난이도가 있는 것은 맞습니다. 오늘은 이걸로 이렇게 해서 만들어봤고요 그래서 이게 뭐냐 하면 셀레늄에서 셀레늄에서 이게 처음에 네이버 데이터 랩 그쪽 사이트에 들어갑니다. 그래서 기기별 성별 연령별 이걸 싹 다 클릭을 해놓고 그다음에 조회하기를 눌러요 그래서 이거를 엑셀 파일 안에다가 Top 500가지를 그걸 집어넣습니다. 해서 뽑기가 키워드를 전체적으로 다 뽑는 걸 완료가 됩니다.
warnings.filterwarnings('ignore')
try:
shutil.rmtree(r"c:\chrometemp") #쿠키 / 캐쉬파일 삭제
except FileNotFoundError:
pass
subprocess.Popen(r'C:\Program Files\Google\Chrome\Application\chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\chrometemp"') # 디버거 크롬 구동
option = Options()
option.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
chrome_ver = chromedriver_autoinstaller.get_chrome_version().split('.')[0]
try:
driver = webdriver.Chrome(f'./{chrome_ver}/chromedriver.exe', options=option)
except:
chromedriver_autoinstaller.install(True)
driver = webdriver.Chrome(f'./{chrome_ver}/chromedriver.exe', options=option)
driver.maximize_window() #최대창
time.sleep(3)
driver.implicitly_wait(10)
action = ActionChains(driver) #액션지정
#################### 네이버 데이터랩 Top 500 키워드 뽑기 ####################
#기기별 전체: //*[@id="18_device_0"]
#성별 전체: //*[@id="19_gender_0"]
#연령 전체: //*[@id="20_age_0"]
#조회하기 클릭: //*[@id="content"]/div[2]/div/div[1]/div/a
driver.get(url='https://datalab.naver.com/shoppingInsight/sCategory.naver')
time.sleep(1)
driver.find_element(By.XPATH, '//*[@id="18_device_0"]').click() #기기별 클릭
#time.sleep(0.5)
driver.find_element(By.XPATH, '//*[@id="19_gender_0"]').click() #성별 클릭
#time.sleep(0.5)
driver.find_element(By.XPATH, '//*[@id="20_age_0"]').click() #연령별 클릭
#time.sleep(0.5)
driver.find_element(By.XPATH, '//*[@id="content"]/div[2]/div/div[1]/div/div/div[1]/div/div[1]/span').click() #분야 클릭
#time.sleep(0.5)
driver.find_element(By.XPATH, '//*[@id="content"]/div[2]/div/div[1]/div/div/div[1]/div/div[1]/ul/li[4]/a').click() #디지털/가전 클릭
#time.sleep(0.5)
driver.find_element(By.XPATH, '//*[@id="content"]/div[2]/div/div[1]/div/a').click() #조회하기 클릭
#time.sleep(1)
#상품정보1 : //*[@id="content"]/div[2]/div/div[2]/div[2]/div/div/div[1]/ul/li[1]/a
#상품정보2 : //*[@id="content"]/div[2]/div/div[2]/div[2]/div/div/div[1]/ul/li[2]/a
#상품정보3 : //*[@id="content"]/div[2]/div/div[2]/div[2]/div/div/div[1]/ul/li[3]/a
from openpyxl import Workbook
wb = Workbook()
ws = wb.create_sheet('keyword')
wb.remove_sheet(wb['Sheet'])
ws.append((['No', '인기검색어']))
for i in range(0, 25) :
for j in range(1, 21) :
path = f'//*[@id="content"]/div[2]/div/div[2]/div[2]/div/div/div[1]/ul/li[{j}]/a'
result= driver.find_element(By.XPATH, path).text
print(result.split('\n'))
time.sleep(0.1)
ws.append(result.split('\n'))
driver.find_element(By.XPATH, '//*[@id="content"]/div[2]/div/div[2]/div[2]/div/div/div[2]/div/a[2]').click()
time.sleep(0.1)
wb.save('C:/Users/user/raw/product_kw/naverdatalabtop500.xlsx')
wb.close()
driver.close()
driver.quit()
print("네이버 데이터랩 Top 500 키워드 뽑기 완료")
time.sleep(3)
파이썬 네이버 데이터랩 Top 500 키워드 검색량 뽑기
이 다음 이후부터는 api를 받아야 됩니다. 네이버 이 다음 거는 파이썬의 네이버 데이터 랩 키워드의 검색량을 뽑는 건데요. 이것도 만만치는 않죠. 그렇지만 이건 api 기준으로 따지고 가져온 거기 때문에 그렇게 그렇게 큰 작업을 요구하거나 이러지는 않습니다. 그냥 이 코드를 그대로 쓰실 때 그냥 api 키하고 customer 키 그냥 그것만 입력만 하면 바로 나오거든요. 그래서 이거는 제가 만들기는 했는데 크게 어렵다거나 이런 거는 아닙니다.
#import pandas as pd
naver_kws = pd.read_excel('C:/Users/user/raw/product_kw/naverdatalabtop500.xlsx')
f = open('C:/Users/user/raw/product_kw/naverdatalabtop500_volumes.csv', 'w', encoding='utf-8-sig') #csv파일 데이터 넣을거 생성
f.write("No,Keyword,SVs"+'\n') #컬럼명 입력
for j in range(0, len(naver_kws)) :
kw = naver_kws.iloc[j]['인기검색어']
BASE_URL = 'https://api.naver.com'
API_KEY = '' #api 키 입력
SECRET_KEY = '' #api 키 입력
CUSTOMER_ID = '' #customer 키 입력
def generate(timestamp, method, uri, secret_key):
message = "{}.{}.{}".format(timestamp, method, uri)
#hash = hmac.new(bytes(secret_key, "utf-8"), bytes(message, "utf-8"), hashlib.sha256)
hash = hmac.new(secret_key.encode("utf-8"), message.encode("utf-8"), hashlib.sha256)
hash.hexdigest()
return base64.b64encode(hash.digest())
def get_header(method, uri, api_key, secret_key, customer_id):
timestamp = str(int(time.time() * 1000))
signature = generate(timestamp, method, uri, SECRET_KEY)
return {'Content-Type': 'application/json; charset=UTF-8', 'X-Timestamp': timestamp, 'X-API-KEY': API_KEY, 'X-Customer': str(CUSTOMER_ID), 'X-Signature': signature}
dic_return_kwd = {}
naver_ad_url = '/keywordstool'
#_kwds_string = '원피스' #1개일경우
#_kwds_string = ['나이키', '원피스', '운동화'] #키워드 여러개일경우
method = 'GET'
prm = {'hintKeywords' : kw , 'showDetail':1}
# ManageCustomerLink Usage Sample
r = requests.get(BASE_URL + naver_ad_url, params=prm, headers=get_header(method, naver_ad_url, API_KEY, SECRET_KEY, CUSTOMER_ID))
r_data = r.json()
#naver_ad_summary = pd.DataFrame(r_data['keywordList'])
#keyword_sv_results = naver_ad_summary[:1] #[:1]
for i in r_data['keywordList'][:1] :
pc = i['monthlyPcQcCnt']
#pc = pc.replace("< 10", "10")
mobile = i['monthlyMobileQcCnt']
#mobile = mobile.replace("< 10", "10")
try :
search_volumnes = str(int(pc) + int(mobile))
except :
search_volumnes = '10'
#print(search_volumnes)
print(str(j)+','+str(kw)+','+str(search_volumnes))
f.write(str(j)+','+str(kw)+','+str(search_volumnes)+'\n')
time.sleep(3) #3초
f.close()
print("네이버 데이터랩 Top 500 키워드 검색량 뽑기 완료")파이썬 네이버 데이터랩 Top 500 키워드 MS SQL에 집어넣기
mssql를 넣었을 때가 애로 사항이 있긴 한데 그중 대표적인 게 키워드를 데이터베이스 안에다가 집어넣었을 때 두 가지 문구가 있습니다. 예를 들면 제가 디렉토리 설정을 잘못 해놨다든가 아니면 캐릭터 셋을 처리를 잘못 해서 에러가 많이 발생하는 경우가 있습니다. 경우는 그 두 가지 에러가 발생된다고 보시면 됩니다. 그래서 아래와 같이 에러 문구가 떴었을 때 어떻게 해야 되냐 이거에 대해서 써놨었고요 그래서 보통은 그 두 가지입니다. 그래서 그 두 가지에서 문제가 터지기 때문에 그것만 염두해 두셔서 가시면 될 것 같아요.
입에 나는 다르게 한번 집어넣을 거야라고 생각하신다면 다르게 집어넣으셔도 상관은 없습니다.
#에러문구1
#(unicode error) 'unicodeescape' codec can't decode bytes in position 222-223: truncated \UXXXXXXXX escape 에러
#디렉토리 경로를 \ <-- / <--- 이렇게 바꿔줘야됨.
#에러문구2
#(20047, b'DB-Lib error message 20047, severity 9:\nDBPROCESS is dead or not enabled\n')
# charset 을 'utf8' 로 처리해주면 됨.
# 이외 bulk insert시 codepage='65001' 을 꼭 넣어줘야됨.그렇게 되는 거고 그다음에 데이터베이스 안에다가 집어넣는 거죠. 이 데이터베이스 안에다가 집어넣는 거는 벌크 인서트로 진행을 했어요. 왜냐하면 이게 데이터를 한 방에 두룩 집어넣을 때가 벌크 인서트가 저는 좋습니다. 그래서 저는 mssql를 사용을 하는데 다른 sql을 사용하는 데이터베이스가 많지 않습니까? 그게 좋다면 그런 걸 사용하셔도 전혀 무관해요. 저는 그냥 뭐 mssql하고 mysql을 많이 그게 많이 편하다 보니까 그거를 조금 많이 사용을 하긴 했습니다.
#import pymssql
#import pandas as pd
# utf8, CP949 로 해야 한글 안 깨짐
conn = pymssql.connect(server='localhost', user='username', password='password', database='mytest' , charset='utf8', autocommit=True)
naver_query = '''
IF OBJECT_ID(N'tempdb..#naver_top500') IS NOT NULL
DROP TABLE #naver_top500
create table #naver_top500 (
No nvarchar(max) null,
keyword nvarchar(max) null,
SVs nvarchar(max) null
)
bulk insert #naver_top500 from 'C:/Users/user/raw/product_kw/naverdatalabtop500_volumes.csv' with (firstrow=2, fieldterminator = ',' ,codepage='65001', rowterminator = '\n', keepnulls )
insert into mytest..naver_top500
select convert(char(10), getdate(), 120) as date,* from #naver_top500
select *
from mytest..naver_top500
with (nolock) ;
'''
# codepage='65001'
data = pd.read_sql(sql=naver_query, con=conn)
conn.commit()
conn.close()
print("네이버 데이터랩 Top 500 키워드 MS SQL에 집어넣기 완료")
파이썬 윈도우 작업 스케쥴러 자동화 작업
그래서 이 데이터베이스를 최종적으로 집어넣고 마찬가지 최종적으로는 파이썬의 윈도우 작업 스케줄러의 자동화 작업입니다.이 작업이 했었을 때 문제점이 하나가 있기는 합니다. 먼저 첫 번째로는 에 보시면 아시겠지만 여기에서 작업 스케줄로 처음에 일반에서 만들 때는 이름하고 설명만 집어넣으면 돼요 그다음에 그 밑에 체크가 해제되어 있는데 가장 높은 수준의 권한으로 실행되어 있는 것도 반드시 체크를 해 주셔야 됩니다.
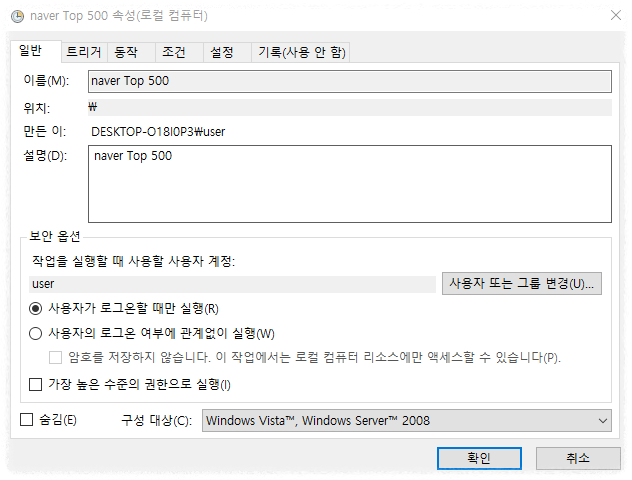
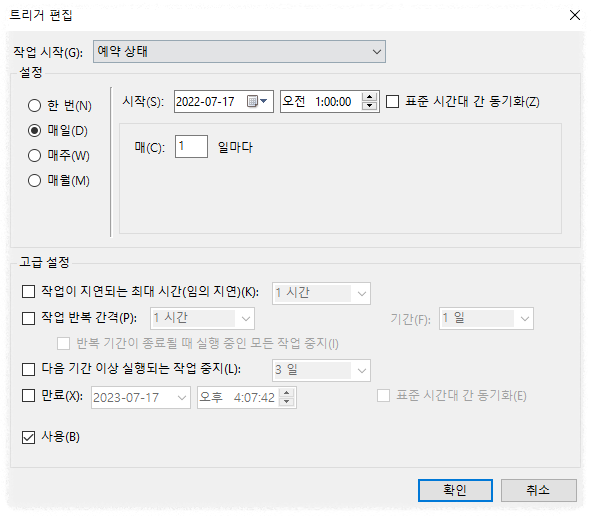
그래서 이 다음은 예약 상태인데 이거는 그냥 자기가 하고 싶을 때마다 자기가 매일 혹은 매주 매월 아니면 뭐 한 번만 할 건지 이것만 설정만 해주시면 돼요 크게 어려운 건 아닙니다.
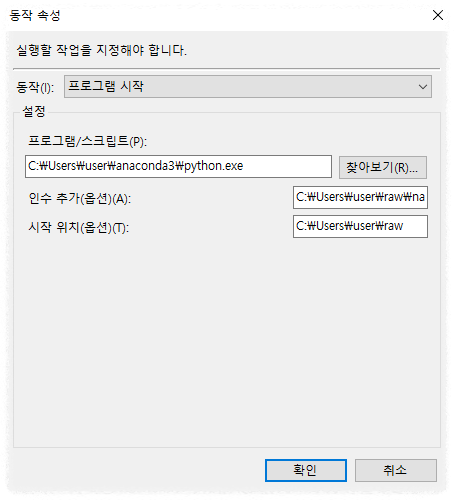
프로그램/스크립트: 파이썬 디렉토리
인수추가: 실행할 파이썬 파일 디렉토리 경로
시작 위치: 실행할 파이썬 파일이 위치한 디렉토리 경로
문제는 동작 속성 여기 부분인데 여기가 동작에서 새로운 것을 만들어 놨을 때 과연 뭘 하느냐 라고 했는데 프로그램 스크립트에 이걸 집어넣을 때는 그냥 파이썬 파일을 집어넣으시면 됩니다. 그다음에 한 가지가 인수 추가 부분 있지 않습니까? 이 인수 추가 부분은 실행해야 될 파이썬 디렉토리 경로를 집어넣어주시면 돼요 그리고 시작 위치도 있으면 편합니다. 시작 위치를 반드시 넣어주셔야 돼요. 시작 위치는 해당 실행해야 할 파이썬 파일이 있지 않습니까? 그 파일에 디렉토리가 어디 있느냐 라는 것을 시장 비치 그 안에 폴더에 집어넣어주면 돼요 이거 안 집어넣으면 셀레늄이 뜨고 보니까 셀레늄이 그냥 둥실둥실 그냥 떠 있기만 하고 실행이 안 되더라고요 그래서 이 시장 위치 부분에서 이걸 넣어주니까 정상적으로 실행이 됐었습니다.
그다음에 마지막으로 조건 부분은 그냥 다 체크를 해지해 주시면 될 것 같고요 마지막 설정 부분도 그냥 아래와 같은 이미지로 작업을 해 주시면 될 것 같습니다.
이렇게 해서 최종적으로 파이에 파이썬 파일로 이걸 만들어 놓고 윈데우 스케줄을 돌려봐요 돌려봐서 각각마다 문제가 있는지 없는지 그냥 이런 것만 파악을 해서 가면은 아마 되지 않을까 싶습니다. 그래서 그게 처음. 그렇게 크게 어렵다거나 이런 거는 없었어요.
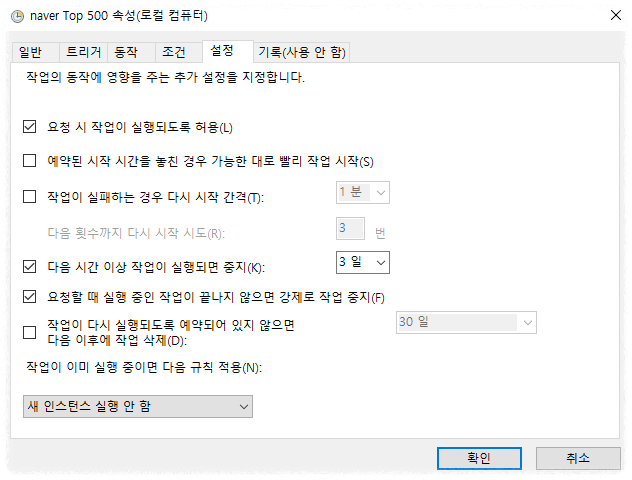
실행할 때 시간이 오래 걸리는 게 짜증 나긴 하는데 그거를 1년의 그냥 과정으로서만 이렇게 해서 그냥 딱딱딱 나눠서 이렇게 처리하면 절대 어려운 작업은 아닙니다. 누구나 다 할 수 있어요. 누구나 다 할 수 있는 그런 거고 다만 시간만 오래 걸릴 뿐 이게 그렇게 어려운 작업은 아닙니다. 오늘은 여기까지입니다. 감사합니다.
'Python' 카테고리의 다른 글
| [파이썬] 구글 트렌드 API 활용해보기 (0) | 2022.07.21 |
|---|---|
| [파이썬] 구글 비즈니스 프로필 API 이용해보기 (0) | 2022.07.20 |
| [파이썬] 판다스 MS-SQL 이용시 한글 깨짐 오류 수정 (0) | 2022.07.16 |
| [파이썬] 핀터레스트 비공식 API 핀 이미지 업로드 오류 해결 (0) | 2022.07.15 |
| [파이썬] 네이버 블로그 방문자 확인 방법 (0) | 2022.07.12 |


댓글